1. 读者对象
本文档面向程序开发人员,有一定的编程基础。最好可以有机器学习、深度学习方面的基础知识。
此文章会是一个vLLM代码解读系列,感兴趣的请持续关注。
2. 概述
2.1 背景
随着大语言模型(LLM)的不断发展,已经在多种领域得到应用,其重要性不言而喻。然而,随着这些模型变得越来越普遍,对GPU资源的需求也随之激增,导致了资源的紧缺。其中,显存中存在许多零散的小块空闲空间,这些空间无法被利用来分配较大的连续内存块,从而降低了显存的使用效率,所以,显存碎片化问题也是原因之一。
显存碎片化主要由动态内存分配、多任务运行和不同内存需求造成。在模型推理或训练过程中,程序会频繁申请和释放显存,导致显存中留下许多无法被重新利用的小块空间。在共享的GPU环境中,多个任务可能会同时运行,每个任务都有自己的显存需求,这可能导致显存分配不均,进一步产生碎片。此外,不同的模型或模型的不同部分可能需要不同大小的显存块,使得难以找到合适的连续空间来满足某些大块内存需求。
这种显存碎片化会降低显存的整体使用率,使得实际可用的显存可能不足以支持大模型的运行,从而会增加模型的推理或训练时间,并限制了可以加载到显存中的模型大小,因为大模型需要连续的大块显存空间。这些因素共同影响了大模型推理或训练的效率和可行性。
为了解决这些问题,vLLM推理加速工具被提出和应用。vLLM是一个快速且易于使用的 LLM 推理和服务库,它在服务吞吐量方面是最先进的框架,同时开创性的使用PagedAttention高效管理注意力键和值内存,并且支持多种量化模型等,不仅如此它还与Hugging Face模型无缝衔接,它的吞吐量比 HuggingFace Transformers 高出 24 倍,而且无需更改任何模型架构;同时,对分布式推理并行支持兼容OpenAI的API服务器,还支持了上百种开源模型。
3. 整体框架
VLLM推理框架通过采用多种技术有效解决了GPU资源紧缺和显存碎片化问题。
首先,VLLM利用虚拟内存管理技术,将GPU显存划分为逻辑块,并使用页表技术将这些逻辑块映射到实际的物理块上。这种方法支持延迟分配、写时复制和块粒度的内存交换,根据实际需求动态分配显存资源,从而避免了内存碎片化并提高了显存利用率。
同时,引入PagedAttention算法允许键值对的非连续存储,通过将键值对划分成多个块并映射到物理块中,实现了键值对的共享和灵活的内存管理,有效避免了显存碎片化。
此外,VLLM通过模型并行和数据并行策略,将大型模型划分为多个子模型,分布在不同的GPU设备上进行并行推理,以及通过智能的数据分发策略进行计算,不仅进一步提高了显存利用率,还减少了GPU设备间的同步开销。这些策略综合提升了vLLM框架处理大规模模型时的效率和性能。
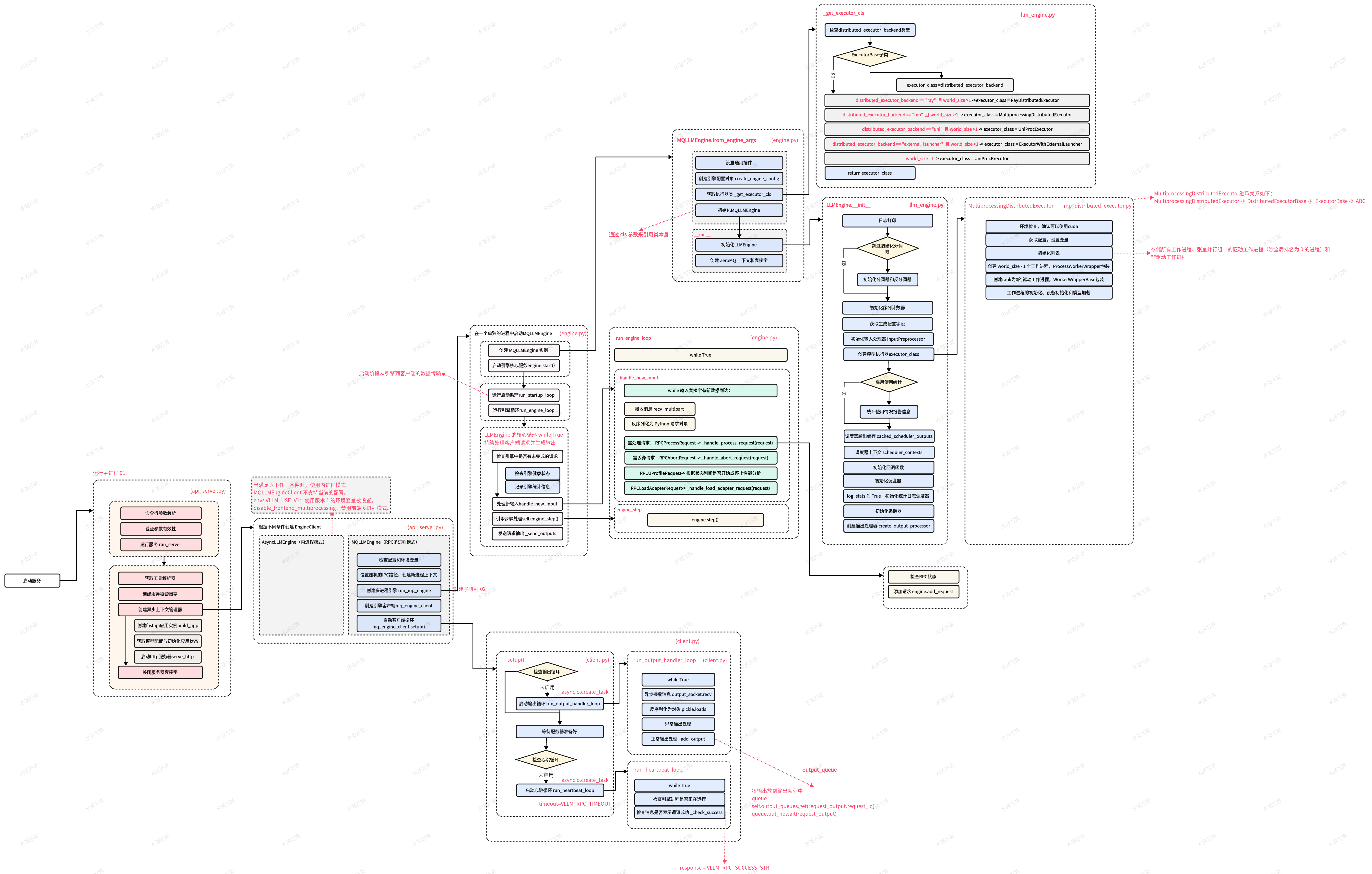
由上图可知,LLMEngine主要由两大部分组成:调度器(Centralized Controller)和分布式系统(Distributed Workers)。
- 调度器的主要作用就是,在每1个推理阶段,决定要把哪些数据送给模型做推理,同时负责给这些模型分配KV Cache物理块,并为这些请求做好逻辑块->物理块的映射。
- 在每1个推理阶段中,分布式执行者(Distributed Workers部分)接收调度器传来的这些请求,分发到各个worker上去做推理(每个worker理解成一块gpu,将使用的模型load到各块卡上)。Worker中的CacheEngine负责实际管理KV Cache;Worker中的model负责加载模型、执行推理,PagedAttention相关的实现和调用就在model下。

4. 虚拟内存管理技术
4.1 使用虚拟内存
如果直接操作物理内存地址,在为进程分配物理内存时,还要考虑别的进程是如何分配物理内存的(已经占用就不能用)。这样不同进程间的耦合性太高了,给开发带来难度。所以,如果能让各个进程间的开发能够相互独立,这样就会方便很多。虚拟内存就能解决:
l 给每个进程分配一个虚拟内存。每个进程在开发和运行时,可以假设这个虚拟内存上只有自己在跑,这样它就能大胆操作。
l 虚拟内存负责统一规划代码、数据等如何在物理内存上最终落盘。这个过程对所有进程来说都是透明的,进程无需操心
4.2 虚拟内存的分段管理
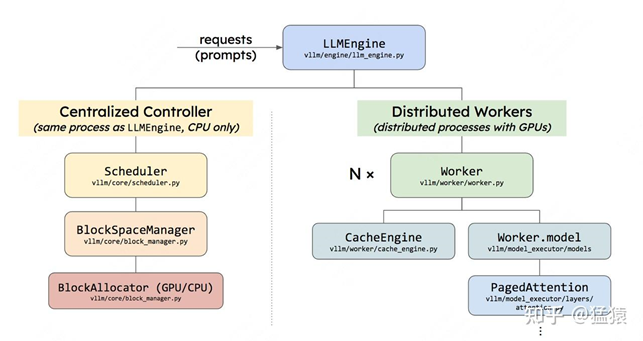
在分段式内存管理中,虚拟内存会尽量为每个进程在物理内存上找到一块连续的存储空间,让进程加载自己的全部代码、数据等内容。
在这个情况下,如果要运行进程4,可以先把进程3从物理内存上交换(swap)到磁盘上,然后把进程4装进来,然后再把进程3从磁盘上加载回来。通过这种方法重新整合了碎片,让进程4能够运行。
但这种办法的显著缺点是:如果进程3过大,同时内存到磁盘的带宽又不够,整个交换的过程就会非常卡顿。这就是分段式内存管理的缺陷。
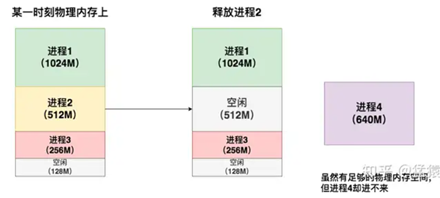
4.3 虚拟内存的分页管理 可以将进程1、进程2想成是两本书。代码分布在书的不同page上。想读哪一页,就加载哪一页,而不是一下把两本书都加载进来。同时,不想读某些页的时候,也能根据页码将其清空。
虚拟内存的分页管理技术总结起来就是:
l 将物理内存划分为固定大小的块,称每一块为页(page)。从物理内存中模拟出来的虚拟内存也按相同的方式做划分;
l 对于1个进程,不需要静态加载它的全部代码、数据等内容。想用哪部分,或者它当前跑到哪部分,就动态加载这部分到虚拟内存上,然后由虚拟内存做物理内存的映射。
对于1个进程,虽然它在物理内存上的存储不连续(可能分布在不同的page中),但它在自己的虚拟内存上是连续的。通过模拟连续内存的方式,既解决了物理内存上的碎片问题,也方便了进程的开发和运行。
5. PagedAttention算法
5.1 原理介绍
5.1.1 单个请求假设向模型server发送一条请求,prompt为“Four score and seven years ago our”,要求模型能做续写。PagedAttention的运作流程如下图:
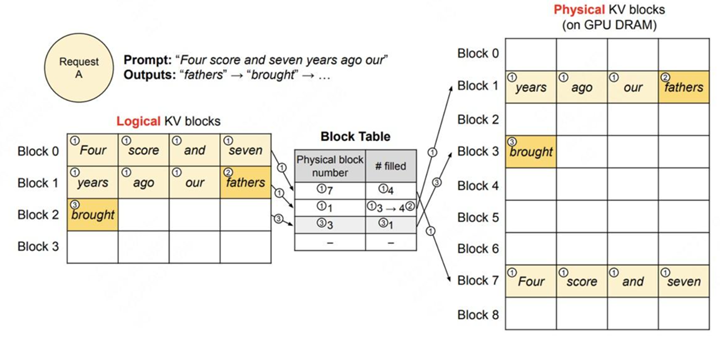
图中带圈的序号表示操作步骤,在图中:
l 请求(request)可理解为操作系统中的一个进程
l 逻辑内存(logical KV blocks)可理解为操作系统中的虚拟内存,每个block类比于虚拟内存中的一个page。每个block的大小是固定的,在vLLM中默认大小为16,即可装16个token的K/V值
l 块表(block table)可理解为操作系统中的虚拟内存到物理内存的映射表
l 物理内存(physical KV blocks)可理解为操作系统中的物理内存,物理块在gpu显存上,每个block类比于虚拟内存中的一个page
(1) Prefill阶段
l 划分逻辑块:vLLM拿到这条prompt,先按照设定好的block大小B(本例中B=4),为prompt划分逻辑块(Logical KV blocks)。由于prompt中有7个token,所以vLLM用2个逻辑块(block 0, block 1)来装它们的KV值。其中,在逻辑块1中目前只装了"years", "ago", "our"这3个token的KV值,有1个位置是空余的。这个位置就被称为保留位(reservation)
l 划分物理块:划分好逻辑块后,就可以将其映射到物理块中去了。物理块是实际存放KV值的地方。我们通过一张block table来记录逻辑块和物理块的映射关系,block table的主要内容包括:
l 逻辑块和物理块的映射关系(physical block number):例如逻辑块0对应物理块7
l 每个物理块上被填满的槽位(# filled):例如在prefill阶段,对物理块7,其4个槽位都被填满;对物理块1,其3个槽位被填满。
l 正常计算prompt的KV值,并通过划分好的关系填入物理块中。
(2) Decode阶段-生成第1个词
l 使用KV cache计算attention,生成第1个词fathers。不难发现,当计算时,使用的是逻辑块,即形式上这些token都是连续的。与此同时,vLLM后台会通过block table这个映射关系,从物理块上获取数据做实际计算。通过这种方式,每个request都会认为自己在一个连续且充足的存储空间上操作,尽管物理上这些数据的存储并不是连续的。
l 基于新生成的词,更新逻辑块、物理块和block table。对于block table,vLLM将它filled字段由3更新至4。
l 分配新的逻辑块和物理块。当fathers更新进去后,逻辑块已装满。所以vLLM将开辟新的逻辑块2,并同时更新对应的block table和物理块。
(3) Deocde阶段-生成第2个词
类比步骤(2)来进行。
5.1.2 多个请求理解方式和单个请求的处理流程一致。所以,通过多个请求(prompt)同时做推理的例子,可以更好感受到PagedAttention是如何通过动态存储KV cache的方式,来更充分利用gpu显存的。
5.2 应用
5.2.1 Parallel Sampling
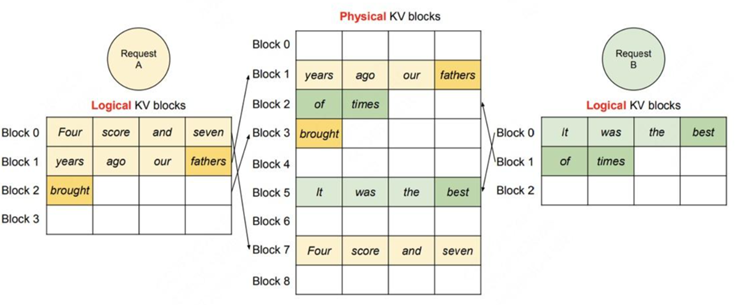
parallel sampling是指给模型发送一个请求,希望它对prompt做续写,并给出三种不同的回答。在这个场景中,可以将prompt复制3次后拼接成1个batch喂给模型,让它做推理。但这种方式会产生prompt部分KV cache的重复存储。
对于传统的KV cache,假设模型的max_seq_len = 2048,可能在显存中分配两块长度是2048的空间。由于prompt一致,这两块2048的空间中存在大量重复的KV cache。
对于vLLM,会按以下两个步骤进行操作:
(1)Prefill阶段,vLLM拿到Sample A1和Sample A2,根据其中的文字内容,为其分配逻辑块和物理块。
l 分配逻辑块:对于A1,vLLM为其分配逻辑块block0和block1;对于A2,vLLM为其分配逻辑块block0和block1。A1的逻辑块和A2的逻辑块是独立的。
l 分配物理块:对于A1和A2,虽然逻辑块独立,但因为它们的文字完全相同,所以可以在物理内存上共享相同的空间。所以A1的逻辑块block0/1分别指向物理块block7/1;A2的逻辑块block0/1分别指向物理块block7/1。设每个物理块下映射的逻辑块数量为ref count,所以对物理块block7/1来说,它们的ref count都为2。
(2)进入decode阶段,A1和A2各自做推理,得到第一个token,分别为fathers和mothers。
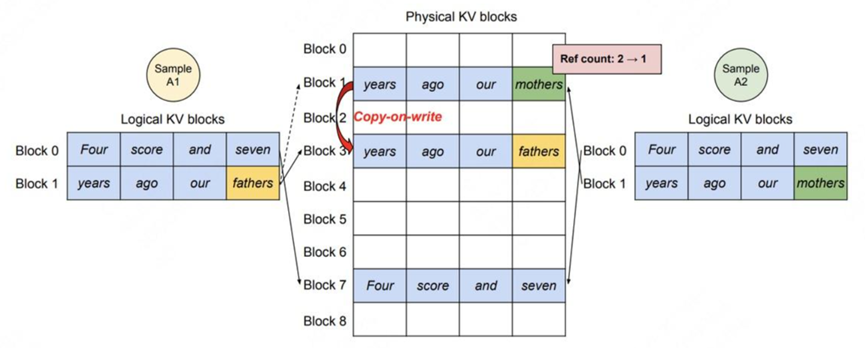
l 将生成的token装入逻辑块:对于A1和A2来说,将其生成的token装入各自的逻辑块block1。
l 触发物理块copy-on-write机制:由于fathers/mothers是两个完全不同的token,因此对物理块block1触发复制机制,即在物理内存上新开辟一块空间。此时物理块block1只和A2的逻辑块block1映射,将其ref count减去1;物理块block3只和A1的逻辑块block1映射,将其ref count设为1。因此,vLLM节省KV cache显存的核心思想是,对于相同数据对应的KV cache,能复用则尽量复用;无法复用时,再考虑开辟新的物理空间。
5.2.2 Beam Search
block皆为逻辑块,假设beam width = 4,即生成了top 4个概率最大的token,在当前解码时刻,它们分别装在block5,block6,block7和block8中。
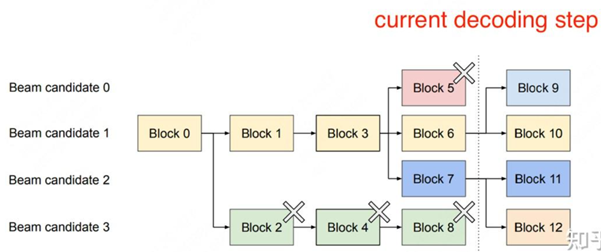
使用beam search算法做decoding,继续找出top 4个最可能的next token。经过top 4 next token,有2个来自beam candidate 1,有2个来自beam candidate 2,block9/10/11/12中装的top 4 next token,就成为新的beam candidates,如上图所示。对于block5和block8,它们已经在beam search的搜索算法中被淘汰了,后续生成的token也不会和它们产生关系,所以可以清除掉这两个逻辑块,并释放它们对应的物理块的内存空间。由于block8已经被淘汰,所以block4也相继被淘汰,并释放对应的物理内存空间。
因此,根据最新时刻的beam search decoding结果,释放掉不再被需要的逻辑块和对应的物理内存空间,达到节省显存的目的。
6. 调度和抢占
当采用动态分配显存的办法时,虽然明面上同一时刻能处理更多的prompt了,但因为没有为每个prompt预留充足的显存空间,如果在某一时刻整个显存被打满了,而此时所有的prompt都没做完推理,这该如何处理。
6.1 原则
当有一堆请求来到vLLM服务器上时,vLLM的调度原则概括如下:
l 先来的请求先被服务(First-Come-First-Serve, FCFS)
l 如有抢占的需要,后来的请求先被抢占(preemption)
暂停这堆请求中最后到达的那些请求的推理,同时将它们相关的KV cache从gpu上释放掉,以便为更早到达的请求留出足够的gpu空间,让它们完成推理任务。如果不这样做的话,各个请求间相互争夺gpu资源,最终将导致没有任何一个请求能完成推理任务。等到先来的请求做完了推理,vLLM调度器认为gpu上有足够的空间了,就能恢复那些被中断的请求的执行了。这样的举动就被称为“抢占(preemption)”。
对于这些因gpu资源不足而被抢占的任务,vLLM要先暂停它们的执行,同时将与之相关的KV cache从gpu上释放掉;然后,等gpu资源充足时,重新恢复它们的执行。针对这两件事,vLLM分别设计了Swapping(交换策略)和Recomputation(重计算策略)来解决。
6.2 数据预处理
由于在vLLM内部计算逻辑中,1个prompt是1个请求。对输入数据做预处理的部分主要是为了完成以下几个目的:
l 每个prompt将被包装成一个SequenceGroup实例提供给调度器做调度
l 1个SequenceGroup实例下维护着若干个Sequence实例,对应着“1个prompt -> 多个outputs"这种更一般性的解码场景。
l 1个Sequence实例下维护着属于自己的逻辑块列表,数据类型为List[LogicalTokenBlock]
在一般的推理场景中,给模型传1个prompt及相关的采样参数,让模型来做推理:
("Hello, my name is",SamplingParams(temperature=0.8, top_k=5, presence_penalty=0.2))
可能会出现“1个prompt à 多个outputs”的情况。所以,需要设计一种办法,对1个prompt下所有的outputs进行集中管理,来方便vLLM更好做推理。那么,SequenceGroup就能起到关键作用。
6.2.1 SequenceGroup的作用
在vLLM中有一个重要假设,即一个seq_group中的所有seq共享1个prompt。"1个prompt -> 多个outputs"这样的结构组成一个SequenceGroup实例。其中每组"prompt -> output"组成一个序列,每个seq下有若干状态(status)属性,包括:waiting、running、swapped和若干和Finish相关的状态(表示该seq推理已经结束)。
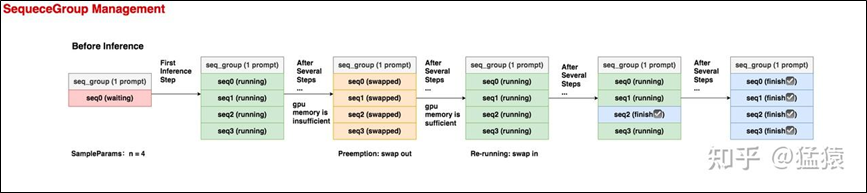
(1) 在推理开始之前,这个seq_group下只有1条seq,就是prompt,状态为waiting。
(2) 在第1个推理阶段,调度器选中了这个seq_group,由于采用参数中n=4,在做完prefill之后,会生成4个seq,状态都是running。
(3) 在若干个推理阶段后,gpu上的资源不够了,这个seq_group被调度器抢占,相关的KV block也被swap out到cpu上,状态变为swapped。但是根据seq数量不同,处理策略有差异:
a. 如果seq数量>1,采取swap策略,即把seq_group下所有的seq的KV cache从gpu上卸载到cpu上;
b. 如果seq数量=1,采取recomputation策略,即把该seq_group相关的物理块都释放掉,然后将它重新放回waiting队列中。等下次它被选中推理时,就是从prefill阶段开始重新推理了,因此被称为“重计算”。
(4) 又过了若干个推理阶段,gpu上的资源又充足了,此时执行swap in操作,将卸载到cpu上的KV block重新读到gpu上,继续对该seq_group做推理,此时seq的状态又变为running。
(5) 又过了若干个推理阶段,该seq_group中有1个seq已经推理完成了,它的状态就被标记为finish,此后这条已经完成的seq将不参与调度。
(6) 又过了若干个推理阶段,这个seq_group下所有的seq都已经完成推理了,这样就可以把它作为最终output返回了。