6.2.2 SequenceGroup的结构
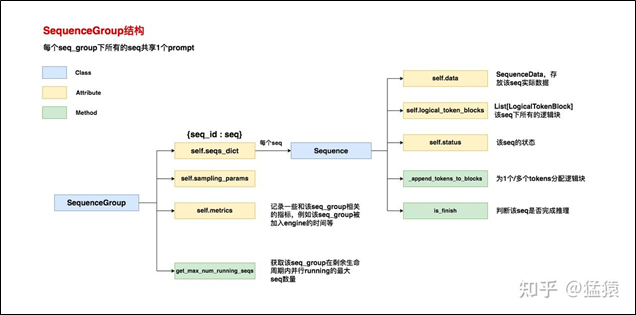
对于结构中的函数解析如下:
l self.seqs_dict:{seq_id: seq},其中每个seq是一个Sequence对象。正如我们前文介绍的那样,一个seq_group下包含若干seqs
l self.sampling_params:采样参数
l self.metrics:记录该seq_group相关的指标,例如该seq_group是什么时候被加入LLMEngine的(arrival_time),该seq_group第一次被调度器选中调度是什么时候等等。调度器在选择时,会参考seq_groups们的这些指标来做决策。
l get_max_num_running_steps:该seq_group在剩余生命周期内并行running的最大seq数量。“剩余生命周期”指从此刻一直到seq_group中所有的seq都做完推理。举个例子来说,我们看2.2节配图中倒数第3个时刻,此时这个seq_group内所有的seq都还没结束推理,所以若调用这个方法,则返回值为4;再看倒数第2个时刻,此时有1个seq已经完成了推理,所以若调用这个方法,则返回值为3。在后续调度策略代码中,我们将经常看到这个方法被调用,目的是用于估计若当前对一个seq_group做推理,它将消耗多少gpu资源。在vLLM中,每个seq都单独维护一份属于自己的逻辑块,不同的逻辑块可以指向同一个物理块。当一个seq只有prompt时,这个方法负责给prompt分配逻辑块;当这个seq开始产出output时,这个方法负责给每一个新生成的token分配逻辑块,整个过程如下图:
6.4 step调度器策略
经过函数add_requests作用后,seq_group都已经被送入调度器(Scheduler)的waiting队列中了。那么,在1个推理阶段中,调度器是通过什么策略来决定要送哪些seq_group进入下一步做推理的。
6.4.1 调度器结构
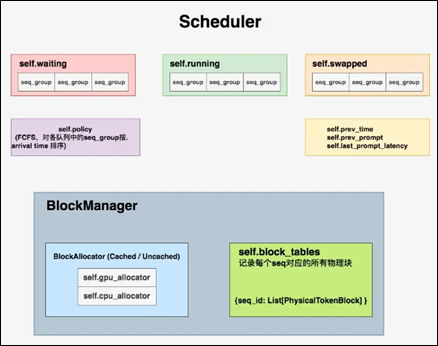
self.waiting, self.running, self.swapped:这三个都是python的deque()实例(双端队列,允许你从队列两侧添加或删除元素):
(1)waiting队列用于存放所有还未开始做推理的seq_group,“未开始”指连prefill阶段都没有经历过。所以waiting队列中的seq_group只有一个seq,即是原始的prompt。
(2)running队列用于存放当前正在做推理的seq_group。
(3)swapped队列用于存放被抢占的seq_group。若一个seq_group被抢占,调度器会对它执行swap或recomputation操作,分别对应着将它送去swapped队列或waiting队列。
self.policy:是vLLM自定义的一个Policy实例,目标是根据调度器总策略(FCFS,First Come First Serve,先来先服务)原则,对各个队列里的seq_group按照其arrival time进行排序。
self.prev_time:上一次调度发起的时间点,初始化为0。我们知道每执行1次推理阶段前,调度器都要做一次调度,这个变量存放的就是上次调度发起的时间点。
self.prev_prompt:取值为True/False,初始化为False。若上一次调度时,调度器有从waiting队列中取出seq_group做推理,即为True,否则为False。
self.last_prompt_latency:记录“当前调度时刻(now) - 最后一次有从waiting队列中取数做推理的那个调度时刻”的差值(并不是每一次调度时,调度器一定都会从waiting队列中取seq_group,它可能依旧继续对running队列中的数据做推理),初始化为0。
BlockManager:物理块管理器,只负责管理和分配物理块,映射关系潜藏在seq中。维护者所有seq_group下seq的物理块,而不是单独某一个seq的。因为整个调度器都是全局的, BlockManager自然也是全局的。物理块管理器这个class下又维护着两个重要属性:
(1)BlockAllocator:物理块分配者,负责实际为seq做物理块的分配、释放、拷贝等操作。其下又分成self.gpu_allocator和self.cpu_allocator两种类型,分别管理gpu和cpu上的物理块。
(2)self.block_tables:负责维护每个seq下的物理块列表,本质上它是一个字典,形式如{seq_id: List[PhysicalTokenBlock]}。
6.4.2 调度策略

l waiting队列中的数据都没有做过prefill,每个seq_group下只有1个seq(prompt)
l running队列中存放着上一个推理阶段被送去做推理的所有seq_group
l swapped队列中存放着之前调度阶段中被抢占的seq_group
running队列中的seq_group不一定能继续在本次调度中被选中做推理,这是因为gpu上KV cache的使用情况一直在变动,以及waiting队列中持续有新的请求进来的原因。所以调度策略的职责就是要根据这些变动,对送入模型做推理的数据做动态规划。
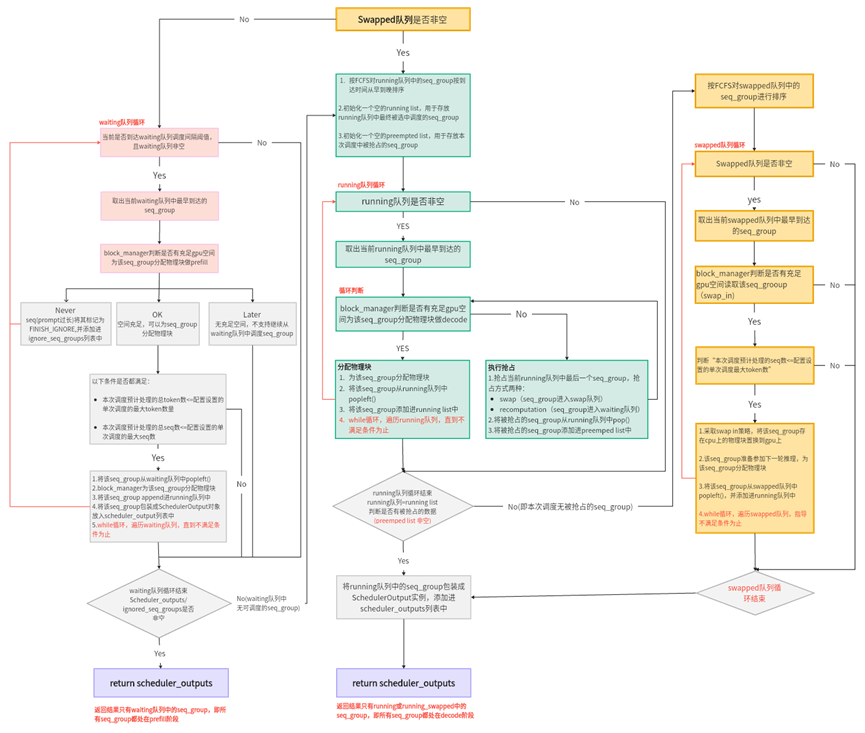
总结来说:
l 如果当前swapped队列为空,那就去检查是否能从waiting队列中调度seq_group,直到不满足调度条件为止(gpu空间不足,或waiting队列已为空等)。此时,1个推理阶段中,所有的seq_group都处在prefill阶段。
l 如果当前swapped队列非空,或者无法从waiting队列中调度任何seq_group时:
Ø 检查是否能从running队列中调度seq_group,直到不满足调度条件为止。
Ø 若本次无新的被抢占的seq_group,且swapped队列非空,就检查是否能从swapped队列中调度seq_group,直到不满足调度条件为止。
6.4.3 BlockManager块管理
BlockManager这个class下又维护着两个重要属性:
(1)BlockAllocator:物理块分配者,负责实际为seq做物理块的分配、释放、拷贝等操作。其下又分成self.gpu_allocator和self.cpu_allocator两种类型,分别管理gpu和cpu上的物理块。
(2)self.block_tables:负责维护每个seq下的物理块列表,本质上它是一个字典,形式如{seq_id: List[PhysicalTokenBlock]}。注意,这个字典维护着所有seq_group下seq的物理块,而不是单独某一个seq的。因为调度器是全局的,所以它下面的的BlockManager自然也是全局的。
其中,BlockAllocator又分成两种类型:
(1)CachedBlockAllocator:按照prefix caching的思想来分配和管理物理块。在原理篇中,我们提过又些prompts中可能含有类似system message(例如,“假设你是一个能提供帮助的行车导航”)E)等prefix信息,带有这些相同prefix信息的prompt完全可以共享用于存放prefix的物理块,这样既节省显存,也不用再对prefix做推理。
(2)UncachedBlockAllocator:正常分配和管理物理块,没有额外实现prefix caching的功能。
当准备从waiting队列中调度seq_group时,会依次做两件事:
Ø 调用self.block_manager.can_allocate(seq_group)方法,判断当前gpu上是否有充足的空间,能为当下这seq_group的prefill阶段分配充足的物理块,用于装其KV Cache
Ø 当下空间充足,则调用self._allocate(seq_group)方法,为waiting队列中的这个seq_group实际分配物理块,这时就会运用到BlockAllocator,并且BlockAllocator的类型不同(即是否做prefix caching),allocate的方法也会不同。
6.4.4 具体函数作用
1. _passed_delay:判断调度waiting队列的时间点
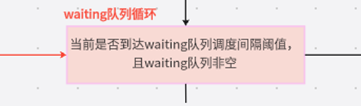
在做推理时,waiting队列中是源源不断有seq_group进来的,一旦vLLM选择调度waiting队列,它就会停下对running/swapped中seq_group的decode处理,转而去做waiting中seq_group的prefill,也即vLLM必须在新来的seq_group和已经在做推理的seq_group间取得一种均衡:既不能完全不管新来的请求,也不能耽误正在做推理的请求。所以“waiting队列调度间隔阈值”就是来控制这种均衡的:
(1)调度间隔设置得太小,每次调度都只关心waiting中的新请求,这样发送旧请求的用户就迟迟得不到反馈结果。且此时waiting队列中积累的新请求数量可能比较少,不利于做batching,浪费了并发处理的能力。
(2)调度间隔设置得太大,waiting中的请求持续挤压,同样对vLLM推理的整体吞吐有影响。
对于这个调度间隔,在代码中也存在函数组进行控制的:self.prev_time、self.prev_prompt和self.last_prompt_latency。
1. can_allocate:能否为seq_group分配物理块做prefill
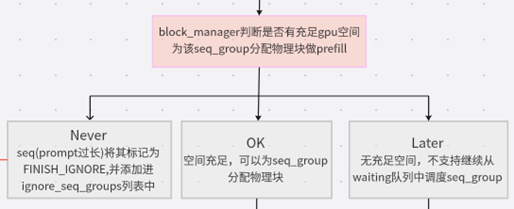
通过了调度时间阈值的判断条件,可以从waiting中取出一个seq_group,将进行prefill操作。所以,先判断:gpu上是否有充足的空间为该seq_group分配物理块做prefill,由self.block_manager来做。
1. can_append_slot:能否为seq_group分配物理块做decode
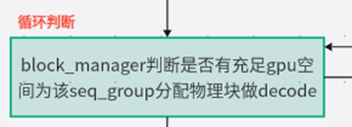
从running队列中调度seq_group时,会判断是否能为该seq_group分配物理块。但这时的物理块空间是用来做decode的(给每个seq分配1个token的位置),而不是用来做prefill的(给每个seq分配若干个token的位置)。所以,判断能否对一个正在running的seq_group继续做推理的最保守的方式,就是判断当前可用的物理块数量是否至少为n。
1. preempt:抢占策略

在若干个推理阶段后,gpu上的资源不够了,这个seq_group不幸被调度器抢占(preemption),它相关的KV block也被swap out到cpu上。此时所有seq的状态变为swapped。这里要注意,当一个seq_group被抢占时,对它的处理有两种方式:
Ø Swap:如果该seq_group剩余生命周期中并行运行的最大seq数量 > 1,此时会采取swap策略,即把seq_group下所有seq的KV block从gpu上卸载到cpu上。(seq数量比较多,直接把算出的KV block抛弃,比较可惜);
Recomputation:如果该seq_group剩余生命周期中并行运行的最大seq数量 = 1,此时会采取recomputation策略,即把该seq_group相关的物理块都释放掉,然后将它重新放回waiting队列中(放在最前面)。等下次它被选中推理时,就是从prefill阶段开始重新推理了,因此被称为“重计算”。(seq数量少,重新计算KV block的成本不高)。
6.5 总结
从vLLM批处理的入口函数开始,调度器有两个重要函数add_request()和step()。
在LLMEngine开始处理请求前(实例化阶段),它会先做一次模拟实验,来估计gpu上需要预留多少显存给KV Cache block。
当LLMEngine开始处理请求时(add_request),它会把每个prompt当成一个请求,同时把它包装成一个SequenceGroup对象。
当LLMEngine开始执行1次调度时(step),调度器策略(Scheduler)会根据实际gpu上KV Cache block的使用情况等要素,来选择要送哪些seq_group去做新一轮推理。在1次推理中,所有seq_group要么一起做prefill,要么一起做decode。
7. 调用方式
根据vLLM的官方文档,它向用户提供了两种调用它的方法,分别是:
l Offline Batched Inference(同步,离线批处理)
l API Server For Online Serving(异步,在线推理服务),在这下面又提供了2种支持的API类型:
l OpenAI-Compatible API Server(官方推荐):兼容了OpenAI请求格式的server,包括OpenAI Completions API和OpenAI Chat API。
l Simple Demo API Server(测试开发用,官方不推荐,相关脚本也不再维护)
在代码实现上,vLLM首先实现了一个推理内核引擎(LLMEngine),在此基础上封装了上述两种调用方法。
7.1 OffLine Batchede Inference
在传统离线批处理中,我们每次给模型发送推理请求时,都要:
l 等一个batch的数据齐全后,一起发送
l 整个batch的数据一起做推理
l 等一个batch的数据全部推理完毕后,一起返回推理结果
这种“团体间等成员到齐,再一起行动”的行为,就被称为“同步”。
在vLLM中,当使用离线批处理模式时,表面上是在做“同步”推理,也即batch_size是静态固定的。但推理内核引擎(LLMEngine)在实际运作时,batch_size是可以动态变更的:在每一个推理阶段(prefill算1个推理阶段,每个decode各算1个推理阶段)处理的batch size可以根据当下显存的实际使用情况而变动。
举个例子来说:
l 给定一个很大的batch,此时尽管vLLM采用了PagedAttention这样的显存优化技术,我们的gpu依然无法同时处理这么大的batch。
l 所以batch中的每一条数据,会被先放到一个waiting队列中。vLLM会用自己的调度策略从waiting队列中依次取数,加入running队列中,直到它认为取出的这些数据将会打满它为1个推理阶段分配好的显存。此时waiting队列中可能还会剩一些数据。
l 在每1个推理阶段,vLLM对running队列中的数据做推理。如果这1个推理阶段执行完毕后,有的数据已经完成了生成(比如正常遇到<eos>了),就将这些完成的数据从running队列中移开,并释放它占据的物理块显存。
l 这时,waiting队列中的数据就可以继续append进running队列中,做下1个阶段的推理。
l 因此在每1个推理阶段,vLLM处理的batch size可能会动态变更。
因此,将LLMEngine包装成离线批处理形式后,所有的数据必须等到一起做完推理才能返给我们。所以从体感上,我们可能很难感知到内核引擎的“动态”逻辑。
正是因为LLMEngine这种“动态处理”的特性,才使得它同时也能成为异步在线服务的内核引擎:当一条条请求发来时,它们都先进入LLMEngine调度器(Scheduler)的waiting队列中(实际并不是直接进入waiting队列中的,而是在传给LLMEngine前先进入asyncio.Queue()中,然后再由LLMEngine调度进waiting队列中的,这些细节我们也放在后面说,这里不影响理解就行)。此时模型正常执行它的1个推理阶段,调度器也正常处理新来的请求。当模型准备执行下1个推理阶段时,调度器再根据设定的策略,决定哪些数据可以进入running队列进行推理。由于在线服务是异步的,先推理完成的数据就可以先发给客户端了(如果采用流式传输,也可以生成多少先发多少)。
在这个过程中,vLLM通过PagedAttention技术和“先来先服务,后来先抢占,gpu不够就先swap到cpu上”的调度策略,在1个推理阶段处理尽可能多的请求,解决高并发场景下的推理吞吐问题。这就是整个vLLM运作的核心思想。
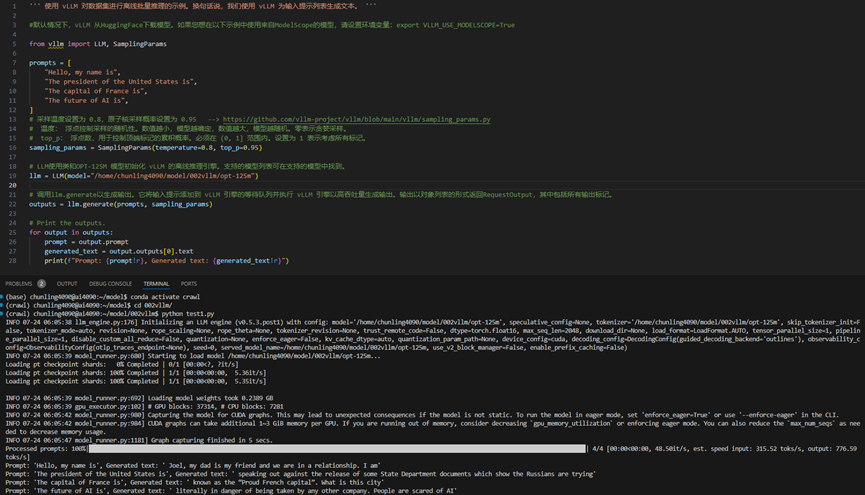
7.2 API Sever For Online Serving
vLLM在实现在线服务时,采用uvicorn部署fastapi app实例,以此实现异步的请求处理。而核心处理逻辑封装在AsyncLLMEngine类中(它继承自LLMEngine)
8. 结果比较
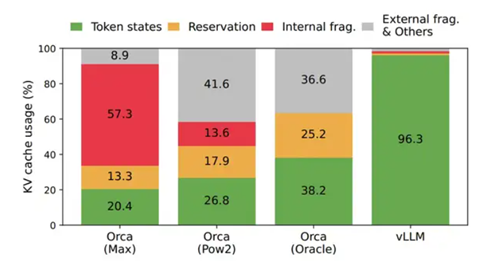
vLLM在显存利用上的改进效果VS 其它推理框架。相比于别的推理框架,vLLM几乎能做到将显存完全打满。
8.1 与ollama比较
1. 文件存储格式:ollama使用自己的格式进行文件存储,而vLLM则可以直接使用从huggingface或者modelscope下载的文件;
2. 数据并发:vLLM在PagedAttention的基础上构建的一个高吞吐量的分布式LLM服务引擎,采用块级内存管理和预先请求调度,实现了KV缓存内存的近零浪费。
3. 显存占用:在相同规格的模型下,ollama的显存占用比vLLM少。此外,当一段时间没有使用ollama时,它会释放显存,而vLLM则不会。这表明ollama在显存管理方面更为高效;
4. 下载模型:ollama默认下载的都是量化版的,因此占用内存显存都小,而vllm下载的都是未经量化的模型,内存和显存占用都大。